Powerful GPU processing delivered on demand to your data
Deploy on-premises or at the edge
MX7000 with CoreModule XL and Liqid SmartStack MX is designed for deployment and installation in a range of environments to bring processing close to the data in order to avoid your valuable and business-critical information leaving your network. Run AI training and inference locally to keep your data secure and contained to your network, whilst enabling business functions to leverage modern AI models to drive growth. Supporting up to 35C ambient temperature, high performance GPU on MX7000 isn’t restricted to core datacenter, but can be deployed to remote locations where required.
Runs AI models of all sizes
Available to configure with a range of standard 350W PCIe dual-slot GPUs from NVIDIA, Intel and AMD, the solution can be configured appropriately for a wide range of workloads in AI, machine learning, rendering and simulation. By combining multiple GPUs in a linked configuration, up to 192GB of unified memory is available for running training and inference on large AI models in order to provide higher accuracy or get a project running with less time required for model optimisation and quantitzation.
Configure dynamically for each job
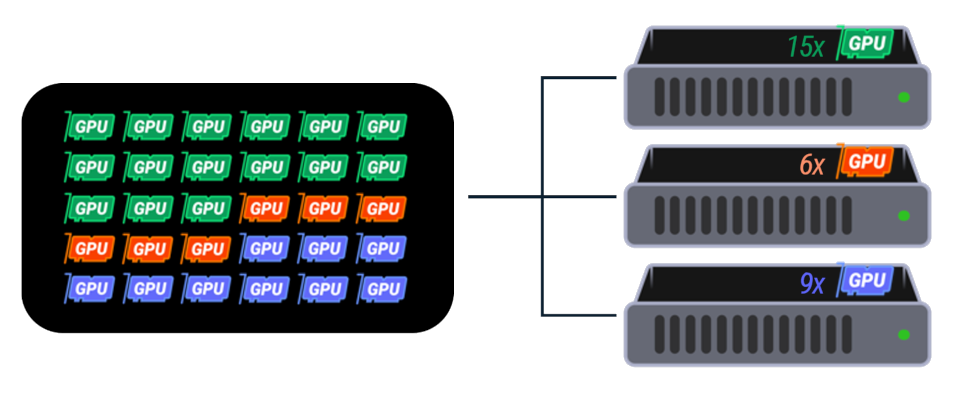
Rather than silo GPU resources in a fixed configuration, Coremodule XL with Liqid Matrix allows the entire pool of GPU resource to be allocated to compute sleds on demand, based on the needs of the current workload. Using the configurable PCIe switch fabric, each GPU is connected directly to the target CPU as a native PCIe device without any virtualisation or bridging layer. This allows the higher level software stack to work as usual without any modification or need to know about the underlying connectivity, so no additional time is required to alter algorithms or models.
Keep your existing models and libraries
Based on standard components and standard architecture, CoreModule XL with Liqid SmartStack requires no modification to existing toolchains, libraries or APIs, so existing models, tools and processing stacks run the same as on any other platform using the same GPUs. This makes it easy to move workloads from an existing GPU platform and take advantage of the composible infrastructure.
Scale with your needs
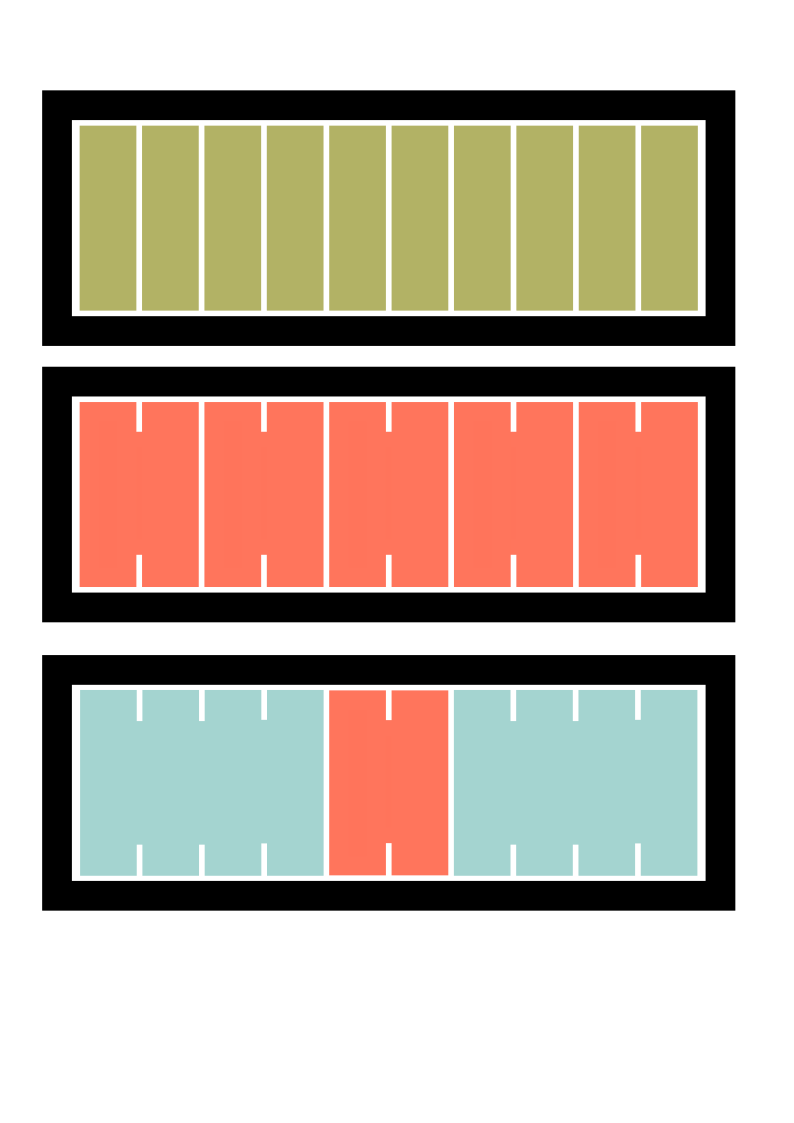
Easy to scale from a single Compute sled connected to a single GPU, all the way up to eight dual-Xeon compute sleds with thirty 350W GPUs, CoreModule XL with Liqid SmartStack MX makes it easy to deploy PowerEdge modular infrastructure suited to any size of workload and task. The system can be upgraded with a single sled or single GPU at a time which join the pool of resources which can be dynamically assigned to work together or with other resources. GPUs which support the linking feature can be setup as dual or quad units to share their memory and work together on larger tasks and broken down again to single GPUs for re-use in a different use case.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}